BIG DATA BIZ.
빅데이터 사업
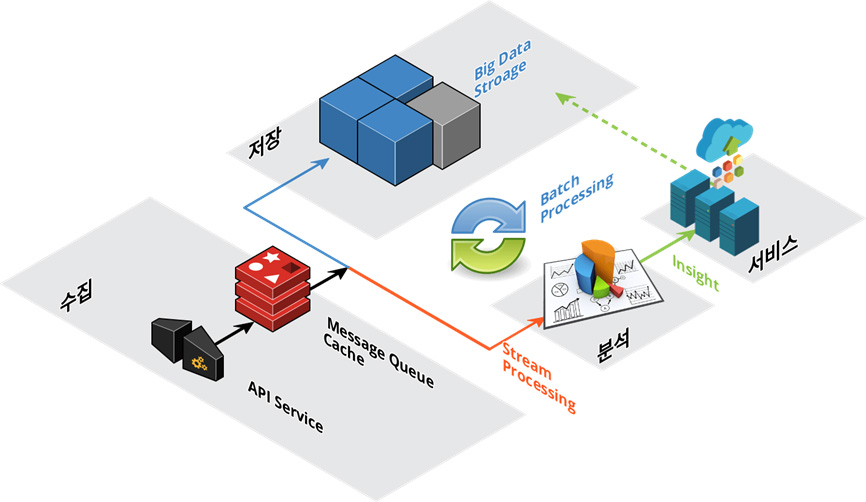
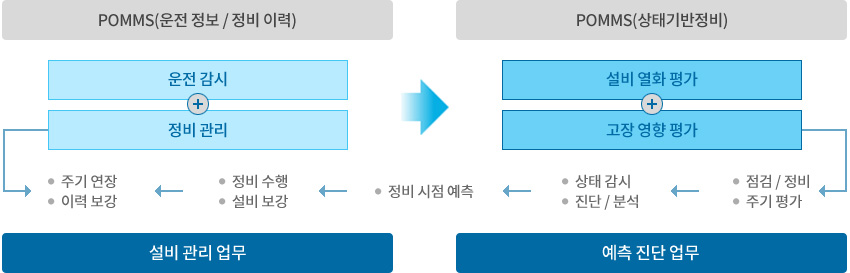
기업 내에서 활용하고자 하는 빅 데이터의 소스 정의
내/외부 소스 데이터 별 수집 및 분석을 위한 원본 데이터 적재
수집/적재 데이터 형태 별 분석 (정형/비정형 분석 또는 정형과 비정형 혼합 분석)
데이터 분석 결과의 다차원 적인활용
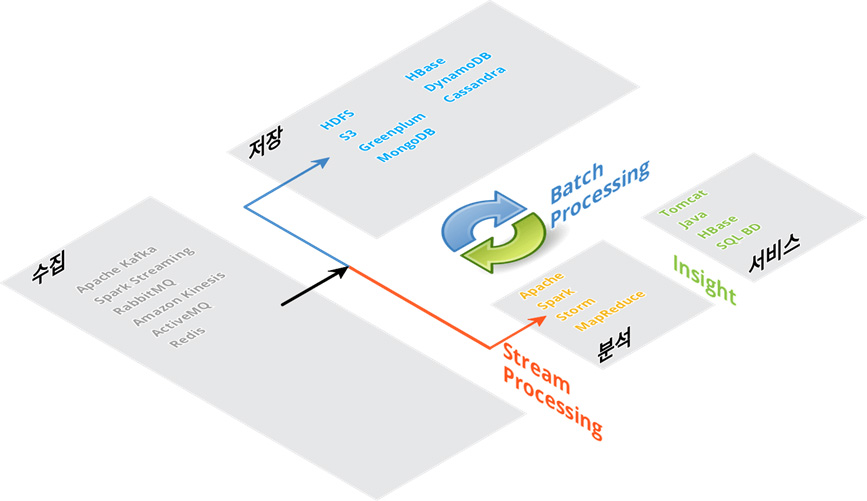
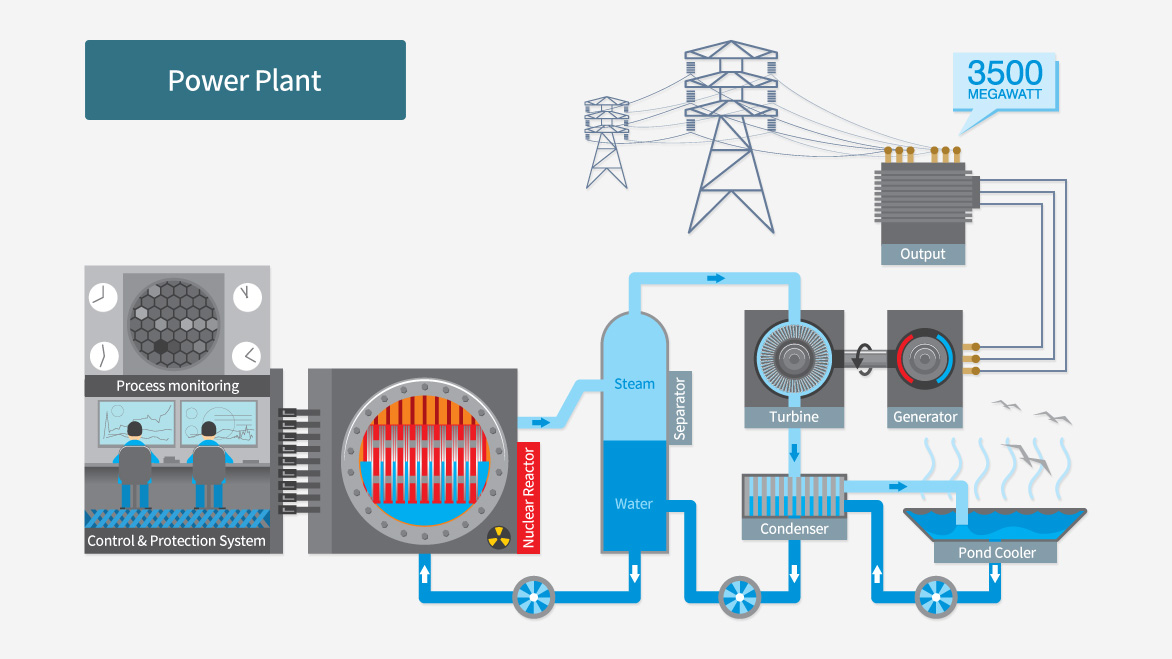
대용량 데이터를 분산 저장 하고 처리합니다. Hadoop HDFS, Hbase, Amazon S3 또는 DynamoDB와 같은 시스템은 큰 데이터를 저장하기에 적합합니다.
기업은 이익을 창출할 수 있는 데이터 기반 결정을 내릴 수 있어야합니다. 데이터 기반 의사 결정을 위해서는 데이터를 시각적으로 잘 표현하는 것이 중요합니다.
데이터에 액세스하고 개발자가 데이터를 사용할 수 있도록 API를 작성합니다. 개발자는 원시 데이터뿐만 아니라 분석 결과를 사용하여 완벽한 응용 프로그램을 구축 할 수 있습니다.
소스의 출처는 모든 형태의 정형, 비정형 데이터 일 수 있으며, 서버 로그, IoT 센서 데이터등 다양합니다. 소스는 API 서비스로 데이터를 보냅니다. API는 데이터를 임시 저장소로 푸시합니다. 임시 저장 장치를 사용하면 다른 단계에서 들어오는 데이터에 간단하고 신속하게 액세스 할 수 있습니다. Apache Kafka, RabbitMQ 또는 AWS Kinesis와 같은 메시징 큐 시스템을 사용합니다.
스트리밍 데이터는 수집에서 가져 와서 분석에 제공됩니다. 스트리밍은 "라이브" 데이터를 분석하므로 빠른 결과를 생성합니다.
일괄 처리를 통해 대용량 데이터 저장소에 액세스하여 많은 양의 데이터 를 취해 분석 할 수 있습니다.
MapReduce, AWS Elastic MapReduce에서 Apache Spark 및 AWS lambda에 이르기까지 다양한 분석도구를 사용할 수 있습니다.